當你從正確的生成器頁面開始時,Happy Horse 1.1 會最好上手。當想法還只存在於提示詞中時,使用 text-to-video;當你已經有一張很強的首幀畫面時,使用 image-to-video;當角色、產品或風格一致性比單純的提示詞自由度更重要時,使用 reference-to-video。
本指南中的截圖擷取自 2026 年 6 月 24 日公開頁面完成載入後的線上 TryHappyHorseAI 生成器。如果你想先看更完整的版本發布總覽,請閱讀 Happy Horse 1.1 已上線:有哪些變化以及如何使用。如果你想在選擇專用頁面之前先比較所有創作模式,也可以從 Happy Horse AI 影片生成器 中樞頁面開始。這篇文章則是實用型搭配指南:該開哪個頁面、哪些設定值得調整、提示詞怎麼寫,以及應該研究哪些範例。
快速工作流程地圖
Happy Horse 1.1 的三個創作頁面之所以分開,是有原因的。它們都能生成影片,但各自預期的起始素材不同。
| 頁面 | 起始素材 | 最適合用於 | 開啟連結 |
|---|---|---|---|
| Text to Video | 書寫好的場景描述 | 概念短片、電影感測試、社群點子、廣告變體 | 文字轉影片 |
| Image to Video | 一張首幀圖片 | 產品動態、人像、海報、視覺循環 | 圖片轉影片 |
| Reference to Video | 最多 9 張參考圖片 | 角色識別、服裝一致性、產品細節、重複使用的行銷活動風格 | 參考圖轉影片 |
要避免的錯誤,是用更長的提示詞去補償錯誤的模式。如果你已經有精確的產品照片,image-to-video 通常會勝過 text-to-video。如果你需要在新場景中保留同一個人或同一套服裝,reference-to-video 通常會比前兩者更合適。
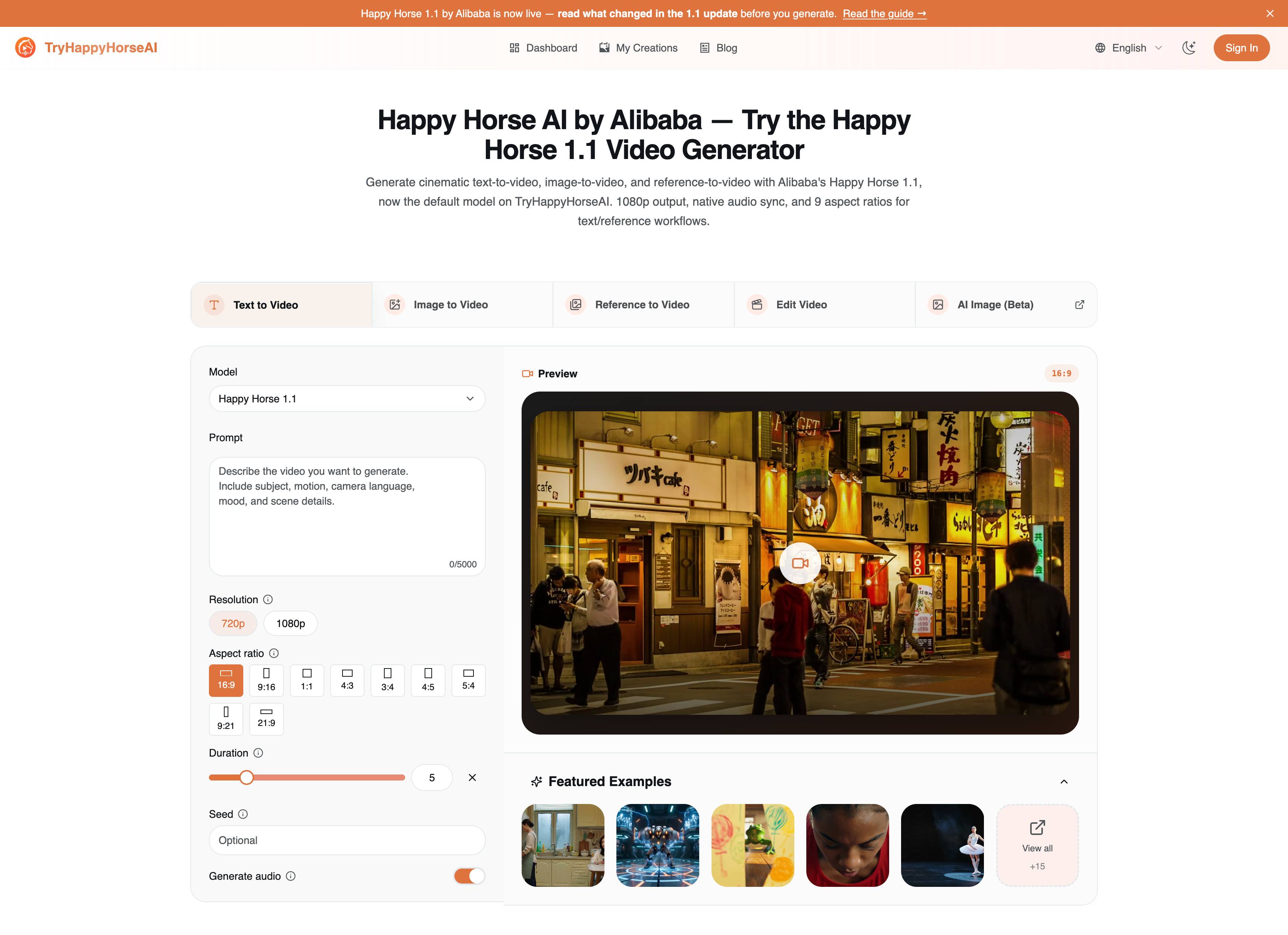
1. Text to Video:從零建立場景
當場景仍有彈性時,請使用 Text to Video。這是探索創意最快的模式,因為提示詞需要承載整個鏡頭:主體、動作、鏡頭、環境、光線、情緒與音訊方向。
此頁面最重要的控制項是:
| 控制項 | 實際用途 |
|---|---|
| Model | 進行新的 T2V 工作時,選擇 Happy Horse 1.1。 |
| Prompt | 描述可見場景、鏡頭運動、氛圍與音訊。 |
| Resolution | 使用 720p 加快迭代,使用 1080p 產出更強的最終渲染效果。 |
| Aspect ratio | 在生成前先選定目標格式:16:9、9:16、1:1、4:3、3:4、4:5、5:4、9:21 或 21:9。 |
| Duration | 選擇 3 到 15 秒的短片長度。 |
| Seed | 當你想要更可重複的變化路徑時,可重複使用同一個 seed。 |
| Generate audio | 當場景需要對白、環境聲或動作音效時,保持開啟。 |
最乾淨的 text-to-video 提示詞公式是:
主體 + 動作 + 環境 + 鏡頭運動 + 光線 + 情緒 + 音訊提示 + 格式
範例:
一位專業芭蕾舞者在昏暗的舞台上完成一個充滿力量的大跳,雙臂伸展,裙擺在慢動作中飄揚。鏡頭從低位側角度跟拍,溫暖的聚光燈在地面投下長長的陰影,電影感舞台燈光,細微的布料動態,10 秒,16:9。
目前精選的 T2V 範例之所以有參考價值,是因為它們展示了不同類型的控制方式:多人對話、打鬥編排、一鏡到底式運動、運動場景,以及芭蕾舞。研究這些範例時,少看主題本身,多看結構:更強的範例會描述場景中有誰、鏡頭如何移動、時間推進中發生了什麼變化,以及音訊應該如何表現。
值得研究的文字轉影片範例
芭蕾舞範例是一個很乾淨的提示詞主導型案例,因為提示詞給出了單一主體、舞台環境、鏡頭風格,以及明確的動作語彙。
多人互動範例則很適合用來理解對話型提示詞。注意它如何把場景、主體、動作與音訊節點分開描述,而不是把整段影片當成一條籠統指令處理。
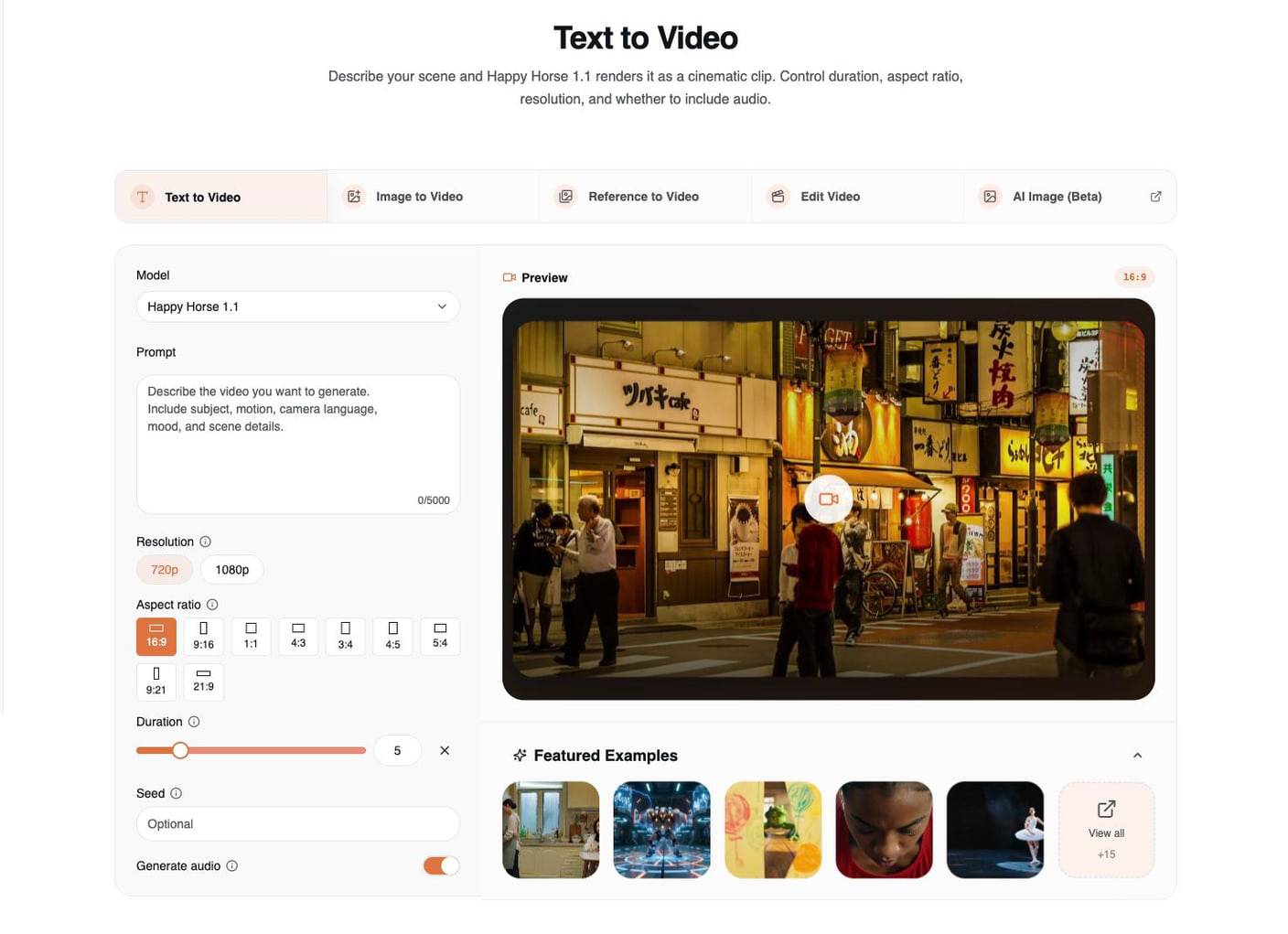
2. Image to Video:讓首幀動起來
當你已經有想要的視覺畫面時,請使用 Image to Video。上傳的圖片本身已經完成了大部分工作,因此提示詞應該引導動態,而不是重新發明整個鏡頭。
當來源圖片已經具備以下條件時,image-to-video 的效果最好:
- 單一且明確的主體
- 乾淨的光線方向
- 清晰可辨的前景與背景景深
- 你希望用於最終影片的裁切構圖
- 足夠的細節,讓模型能保留角色識別或產品形狀
實用的提示詞公式是:
保留上傳圖片 + 加入合理動態 + 加入鏡頭運動 + 保護關鍵細節
產品圖片範例:
讓首幀中的香水瓶以緩慢且具電影感的方式推近,底部周圍漂浮柔和的琥珀色薄霧,玻璃表面有細微的光影掃過,真實反射,保留瓶身形狀、標籤、顏色與桌面構圖。
人像範例:
讓這張人像出現細微眨眼、自然呼吸、輕柔髮絲動態,以及緩慢的鏡頭漂移。保留臉部、服裝、背景構圖與原始光線。
在這個模式下,請在上傳前先完成裁切。如果你要做直式短片,就準備直式首幀;如果你要做寬螢幕落地頁循環背景,就準備寬螢幕首幀。Image-to-video 並不是要求模型大幅重構已完成構圖的地方。
目前精選的 I2V 範例,是不同來源圖片任務的良好參考:教室動作場景、細節豐富的手作畫面、香水產品照,以及古代酒館風格場景。其模式很一致:先有強來源圖,再加入克制的動態。
值得研究的圖片轉影片範例
香水範例是最容易重複套用到商業工作的 I2V 模式:保留產品、加入氛圍,然後讓鏡頭與光線動態去營造高級感。
教室打鬥範例則是較高難度的 I2V 案例。它的價值在於,提示詞把細節預算放在因果動作、環境互動與鏡頭同步上。
若要深入了解這個工作流程,請閱讀 Happy Horse AI 圖片轉影片:完整指南與範例。
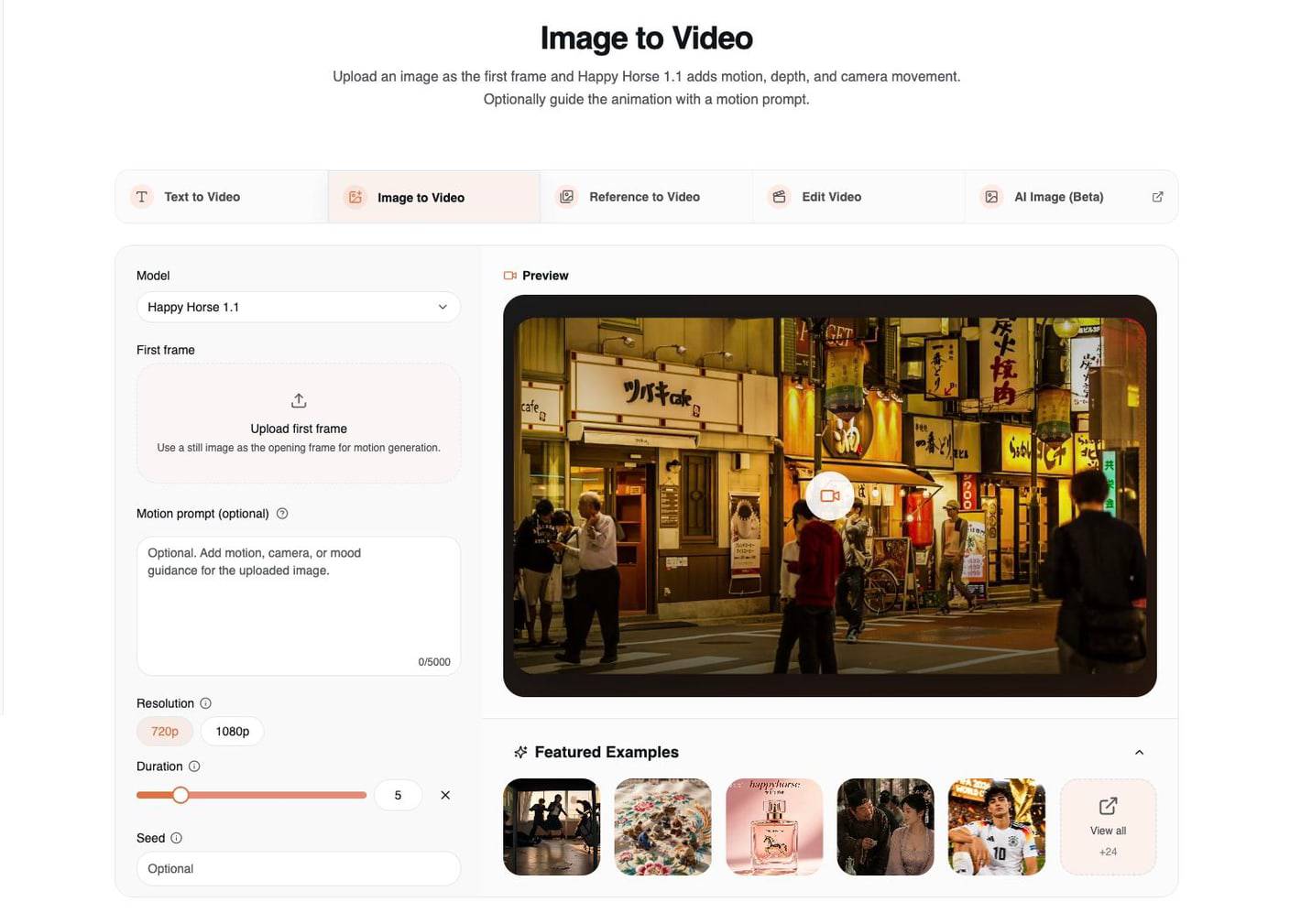
3. Reference to Video:保留角色識別與風格
當單靠提示詞還不夠時,請使用 Reference to Video。這個模式可讓你上傳多張參考圖,並描述它們應如何控制生成出的影片。
在這個工作流程中,Happy Horse 1.1 最多支援 9 張參考圖片。重點不只是上傳圖片,更是要在提示詞中清楚標示它們的角色。
請使用以下結構:
Use character1 for [identity/face/outfit].
Use character2 for [second person or creature].
Use image3 for [location/product/style].
Describe the action, camera, lighting, and audio.
範例:
Use character1 as the swordsman, preserving his face, black robe, and silver hair. Use character2 as the dragon princess, preserving her crown and scale-like shoulder armor. They face each other in a rainy palace courtyard, slow circular camera movement, dramatic lantern light, restrained martial arts motion, cinematic fantasy realism, 16:9.
Reference-to-video 最適合用於:
- 跨場景維持角色一致性
- 多角色敘事
- 必須保持產品可辨識度的產品影片
- 需要穩定服裝與臉部細節的 influencer 或主持人概念
- 需要重複相同視覺語言的廣告活動
目前精選的 R2V 範例涵蓋了正確的範圍:武俠場景、奇幻角色配對、表情變化、直播帶貨展示,以及聚焦物件的提示詞。研究這些範例時,請注意文字如何指派參考圖角色。像「use these images」這種模糊提示,會比「use character1 for identity, image2 for outfit, and image3 for product shape」弱得多。
值得研究的參考圖轉影片範例
武俠範例是一個直接的角色映射案例:image1 與 image2 被視為兩位對戰者,而提示詞則定義共用的場景與動作。
直播帶貨範例則說明了為什麼 R2V 的用途不只限於奇幻或動作題材。提示詞將參考圖映射到主持人、服裝、產品與居家場景,接著再給出有時間節奏的台詞節點。
三個頁面都重要的設定
大多數生成失敗,來自意圖與設定不匹配,而不是提示詞裡某個形容詞寫得不好。
| 設定 | 建議使用方式 |
|---|---|
| Duration | 測試時先從 5 秒開始。當動作需要時間展開時,使用 8 到 10 秒。避免在 3 秒內要求太多動作節點。 |
| Resolution | 先用 720p 迭代;當概念值得精修時,再升到 1080p。 |
| Aspect ratio | 對於 text-to-video 與 reference-to-video,請在生成前先設定最終平台比例。對於 image-to-video,請先把首幀準備成你需要的裁切比例。 |
| Seed | 只有在你已經找到值得深入探索的提示詞方向後再使用。它更適合做受控變化,而不是拯救薄弱的提示詞。 |
| Audio | 當場景包含對話、環境音、音樂或動作音效時,請開啟音訊。如果你需要無聲的視覺循環,請直接在提示詞中說明。 |
| Reference images | 與其一開始就上傳滿 9 張,不如先使用更少但更清楚的參考圖。每一張參考圖都應該有明確任務。 |
如果你正在從零開始撰寫提示詞,可以搭配開著 50 個真的有效的 Happy Horse AI 提示詞 一起使用。那裡的範例屬於較舊的 1.0 模式,但提示詞結構依然很適合轉移到 1.1。
可重複使用的提示詞模板
文字轉影片模板
[Subject] is [action] in [environment]. The camera [movement], with [lighting] and [mood]. Include [audio cue]. Keep [style constraint]. Format: [aspect ratio], [duration].
圖片轉影片模板
Animate the uploaded image with [small motion], [camera movement], and [environmental detail]. Preserve [identity/product shape/composition/lighting]. Avoid changing [protected detail].
參考圖轉影片模板
Use character1 as [role] and preserve [identity details]. Use image2 as [style/location/product reference]. Create [scene action] with [camera movement], [lighting], and [audio/mood]. Keep all key references consistent.
常見錯誤
錯誤 1:要求 text-to-video 維持固定角色識別。
如果角色識別必須保持穩定,請改用 reference-to-video。
錯誤 2:上傳品質不佳的首幀。
Image-to-video 無法可靠地修正糟糕的光線、混亂的構圖,或不清楚的主體識別。
錯誤 3:因為能用就把所有參考圖都上傳。
雖然最多可用九張參考圖,但三張清楚的參考圖通常比九張重複冗餘的圖更有效。
錯誤 4:忘記目標格式。
TikTok 風格的直式影片與 YouTube 風格的寬螢幕短片,不應該從同一個比例開始。
錯誤 5:在短時長內塞太多內容。
不要在 5 秒片段中要求五種鏡頭移動、三種情緒和完整動作序列。選出唯一真正重要的那一刻。
建議起手配方
| 目標 | 頁面 | 起始設定 | 提示詞方向 |
|---|---|---|---|
| 快速概念場景 | Text to Video | 720p、5 秒、目標比例 | 清楚主體、一個動作、一個鏡頭移動 |
| 社群廣告產品循環 | Image to Video | 產品圖片、最終 1080p | 保留產品,加入薄霧/光掃/緩慢推近 |
| 角色劇情節點 | Reference to Video | 2 到 4 張參考圖、5 到 8 秒 | 映射 character1、character2、location/style |
| 對話或氛圍測試 | Text or Reference | 開啟音訊、5 到 8 秒 | 直接寫出對白或聲音氛圍 |
| 行銷活動一致性 | Reference to Video | 各次嘗試使用同一組參考圖 | 固定參考角色,變化場景動作 |
FAQ
哪一種 Happy Horse 1.1 模式最適合作為起點?
如果你只有一個想法,從 text-to-video 開始;如果你已經有完成的靜態圖片,從 image-to-video 開始;如果角色識別、產品形狀、服裝或風格一致性很重要,則從 reference-to-video 開始。
Happy Horse 1.1 支援 image-to-video 嗎?
支援。Happy Horse 1.1 在專用的 圖片轉影片 頁面提供 image-to-video。上傳一張首幀後,再用動態提示詞描述鏡頭運動與場景動態。
我可以使用多少張參考圖片?
Happy Horse 1.1 的 reference-to-video 工作流程最多支援 9 張參考圖片。請在提示詞中使用像 character1、character2 或 image3 這樣清楚的角色標籤,讓模型知道每張參考圖控制什麼。
我應該使用 720p 還是 1080p?
使用 720p 來更快測試提示詞,等你準備好精修一個強方向時,再切換到 1080p。解析度無法修補薄弱的提示詞,因此在投入更高最終品質之前,先把場景結構迭代好。
Happy Horse 1.1 會取代 video edit 嗎?
目前還不能涵蓋所有工作流程。Happy Horse 1.1 現在是 text-to-video、image-to-video 與 reference-to-video 的預設模式。如果你需要編輯既有影片,請先使用現有的 video-edit 工作流程,直到 1.1 的 edit 支援被納入公開生成器流程。
試試這三個 Happy Horse 1.1 頁面
最簡單的下一步,就是打開與你的起始素材相符的頁面:
如果你還在判斷模型本身到底改了什麼,先從 Happy Horse 1.1 發布指南 開始,再回到這裡並排測試這三種工作流程。