Happy Horse 1.1 è più facile da usare quando si parte dalla pagina del generatore giusta. Usa text-to-video quando l’idea esiste solo come prompt, image-to-video quando hai già un primo fotogramma forte e reference-to-video quando la coerenza di personaggio, prodotto o stile conta più della pura libertà del prompt.
Abbiamo acquisito gli screenshot di questa guida dal generatore TryHappyHorseAI live il 24 giugno 2026, dopo che le pagine pubbliche avevano terminato il caricamento. Se vuoi prima una panoramica più ampia del rilascio, leggi Happy Horse 1.1 è live: cosa è cambiato e come usarlo. Puoi anche partire dall’hub del generatore video Happy Horse AI se vuoi confrontare tutte le modalità di creazione prima di scegliere una pagina dedicata. Questo articolo è il complemento pratico: quale pagina aprire, quali impostazioni toccare, come scrivere il prompt e quali esempi studiare.
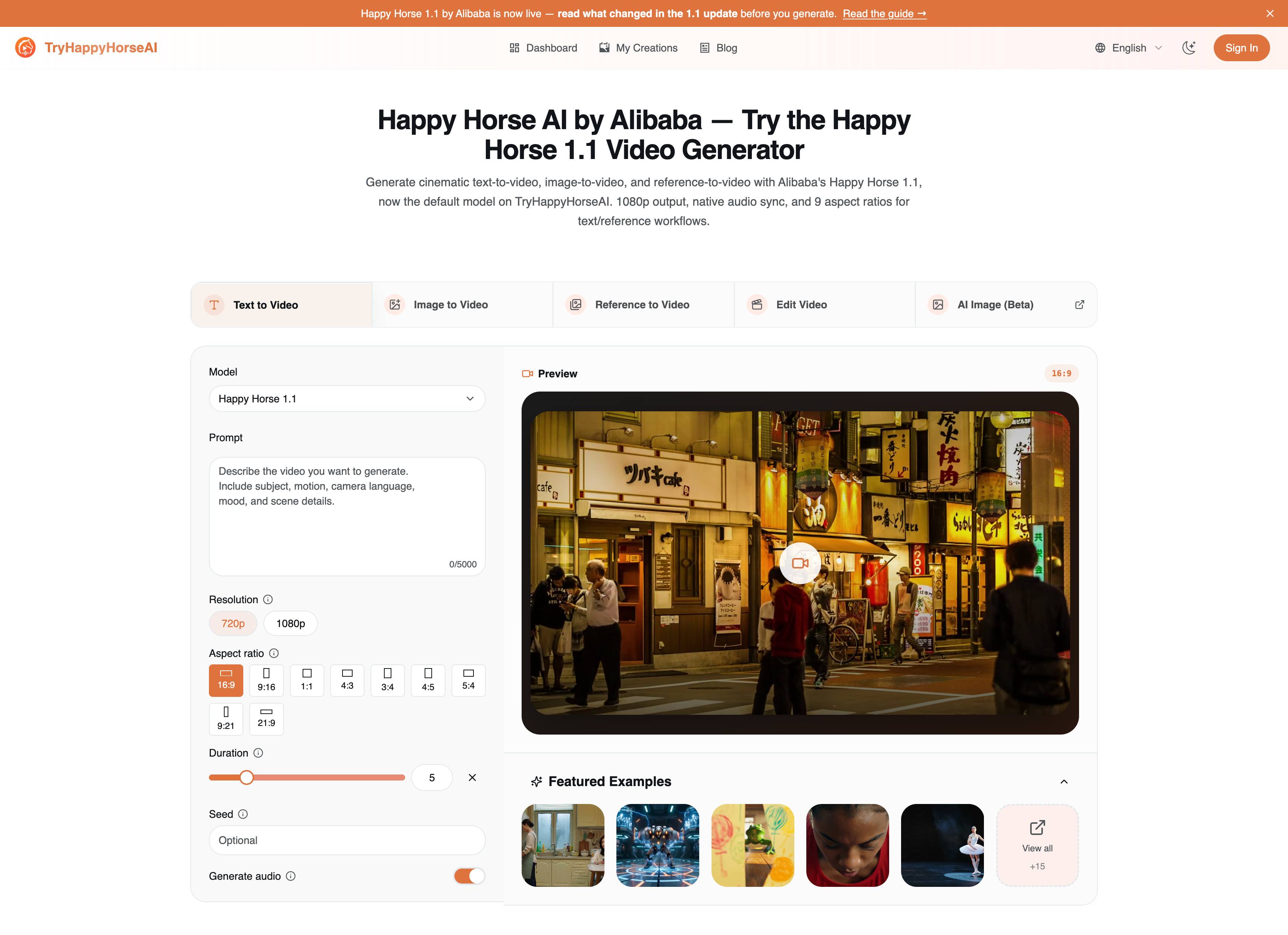
La Mappa del Flusso di Lavoro Rapido
Le tre pagine di creazione di Happy Horse 1.1 sono separate per un motivo. Tutte generano video, ma ognuna si aspetta una risorsa iniziale diversa.
| Pagina | Inizia con | Ideale per | Aprila |
|---|---|---|---|
| Text to Video | Una scena scritta | Clip concettuali, test cinematografici, idee social, varianti adv | Text to Video |
| Image to Video | Un’immagine primo frame | Movimento di prodotto, ritratti, poster, loop visivi | Image to Video |
| Reference to Video | Fino a 9 immagini reference | Identità del personaggio, guardaroba, dettagli prodotto, stile di campagna ripetuto | Reference to Video |
L’errore da evitare è usare un prompt più lungo per compensare la modalità sbagliata. Se hai già la foto esatta del prodotto, image-to-video di solito supererà text-to-video. Se hai bisogno che la stessa persona o lo stesso outfit vengano preservati in una nuova scena, reference-to-video di solito supererà entrambe.
1. Text to Video: Crea la Scena da Zero
Usa Text to Video quando la scena è ancora flessibile. Questa è la modalità più veloce per esplorare idee perché il prompt porta l’intera inquadratura: soggetto, azione, camera, ambiente, illuminazione, mood e direzione audio.
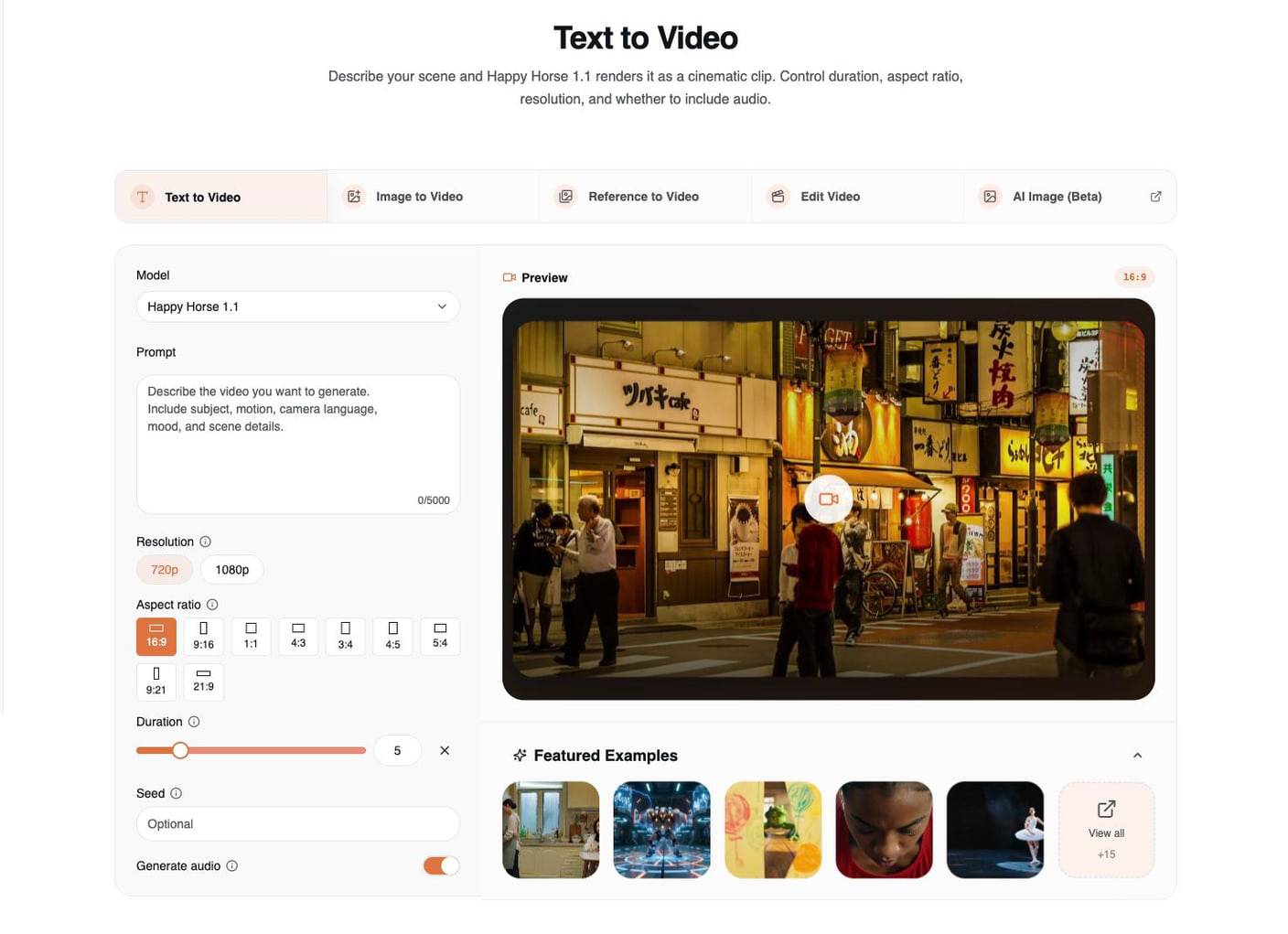
I controlli più importanti in questa pagina sono:
| Controllo | Uso pratico |
|---|---|
| Model | Scegli Happy Horse 1.1 per nuovi lavori T2V. |
| Prompt | Descrivi la scena visibile, il movimento di camera, il mood e l’audio. |
| Resolution | Usa 720p per iterare più velocemente e 1080p per render finali più solidi. |
| Aspect ratio | Scegli il formato di destinazione prima della generazione: 16:9, 9:16, 1:1, 4:3, 3:4, 4:5, 5:4, 9:21 o 21:9. |
| Duration | Scegli una durata breve della clip da 3 a 15 secondi. |
| Seed | Riutilizza un seed quando vuoi un percorso di variazione più ripetibile. |
| Generate audio | Lascialo attivo quando la scena beneficia di dialoghi, ambiente o suoni d’azione. |
La formula più pulita per un prompt text-to-video è:
Soggetto + azione + ambiente + movimento di camera + illuminazione + mood + indicazione audio + formato
Esempio:
Una ballerina di danza classica professionista esegue un potente grand jeté su un palco poco illuminato, con le braccia distese e il tutù che fluisce al rallentatore. La camera segue da un angolo laterale basso, caldi riflettori creano lunghe ombre sul pavimento, illuminazione scenica cinematografica, leggero movimento del tessuto, 10 secondi, 16:9.
Gli esempi T2V attualmente in evidenza sono utili perché mostrano diversi tipi di controllo: dialogo tra più persone, coreografia di combattimento, movimento in piano sequenza, movimento sportivo e balletto. Quando li studi, guarda meno il soggetto e più la struttura: gli esempi migliori descrivono chi è nella scena, come si muove la camera, cosa cambia nel tempo e cosa dovrebbe fare l’audio.
Esempi text-to-video da studiare
L’esempio del balletto è un caso pulito di prompt-first perché il prompt fornisce un unico soggetto, un ambiente di palcoscenico, uno stile di camera e un vocabolario di movimento chiaro.
L’esempio di interazione tra più persone è utile per i prompt in stile dialogo. Nota come il prompt separi scena, soggetti, movimento e battute audio invece di trattare l’intera clip come un’unica istruzione generica.
2. Image to Video: Anima un Primo Fotogramma
Usa Image to Video quando hai già il frame visivo che desideri. L’immagine caricata svolge gran parte del lavoro, quindi il prompt dovrebbe guidare il movimento invece di reinventare l’inquadratura.
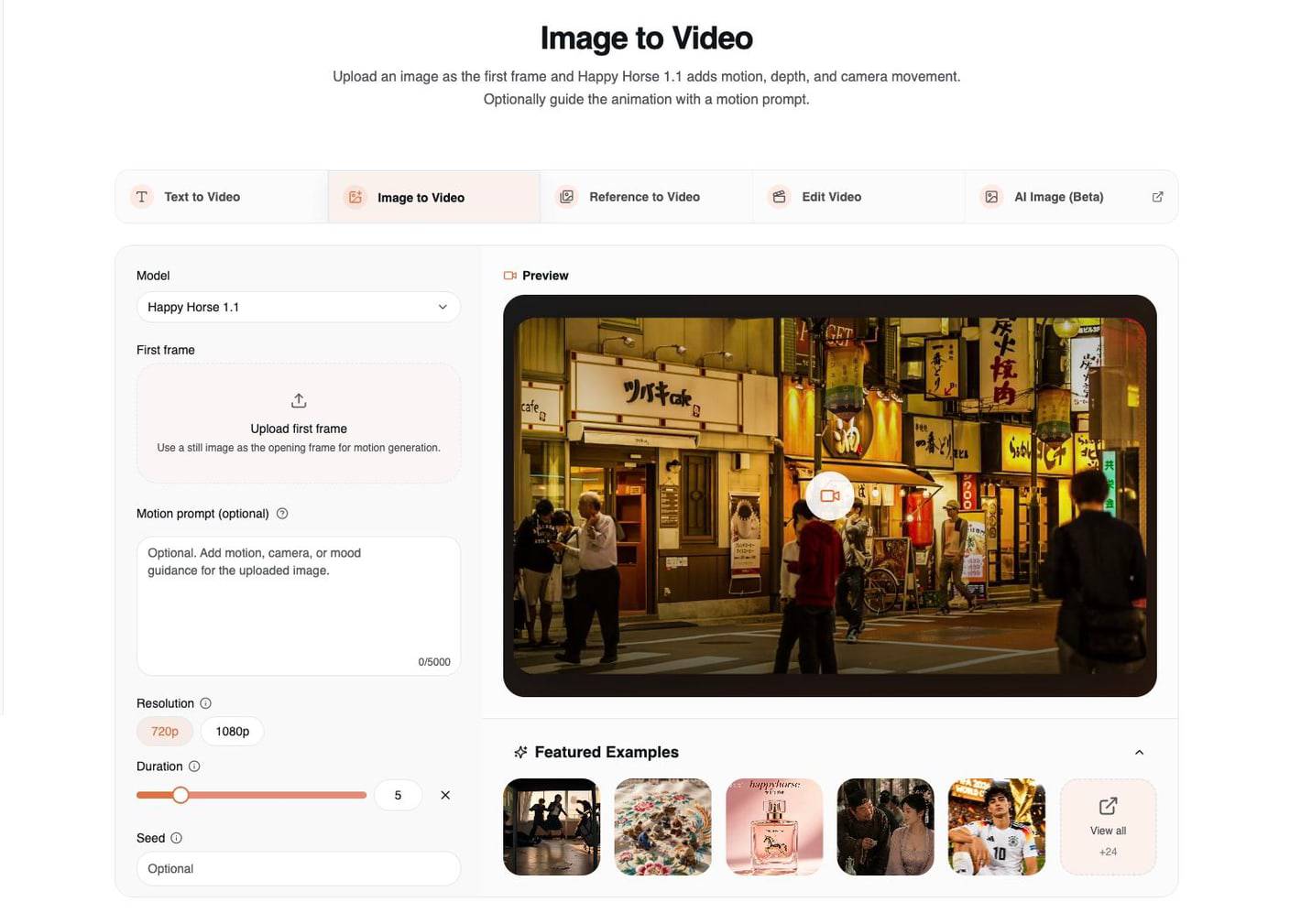
Image-to-video dà il meglio quando l’immagine sorgente ha già:
- un soggetto chiaro
- una direzione della luce pulita
- profondità leggibile tra primo piano e sfondo
- il ritaglio che vuoi per il video finale
- abbastanza dettaglio perché il modello preservi identità o forma del prodotto
La formula pratica del prompt è:
Preserva l’immagine caricata + aggiungi un movimento logico + aggiungi movimento di camera + proteggi i dettagli chiave
Esempio per l’immagine di un prodotto:
Anima il flacone di profumo del primo frame con un lento avvicinamento cinematografico, una morbida foschia ambrata che si muove attorno alla base, un leggero passaggio di luce sul vetro, riflessi realistici, preserva la forma del flacone, etichetta, colore e composizione sul piano d’appoggio.
Esempio per un ritratto:
Anima il ritratto con battiti di ciglia discreti, respirazione naturale, leggero movimento dei capelli e un lento drift della camera. Preserva il volto, l’outfit, la composizione dello sfondo e l’illuminazione originale.
Per questa modalità, esegui il crop prima dell’upload. Se vuoi uno short verticale, prepara un primo frame verticale. Se vuoi un loop widescreen per una landing page, prepara un primo frame widescreen. Image-to-video non è il posto giusto per chiedere al modello di rifare radicalmente il framing di una composizione già finita.
Gli esempi I2V attualmente in evidenza sono buoni riferimenti per diversi tipi di immagini sorgente: una scena d’azione in aula, un’immagine artigianale dettagliata, uno scatto di prodotto di profumo e una scena in stile antica taverna. Il pattern è coerente: prima un’immagine sorgente forte, poi un movimento contenuto.
Esempi image-to-video da studiare
L’esempio del profumo è il pattern I2V più facile da riutilizzare per lavori commerciali: preserva il prodotto, aggiungi atmosfera, poi lascia che il movimento di camera e luce creino la sensazione premium.
L’esempio del combattimento in aula è un caso I2V più complesso. È utile perché il prompt spende il suo budget di dettaglio su azione causa-effetto, interazione con l’ambiente e sincronizzazione della camera.
Per una guida più approfondita su questo workflow, leggi Happy Horse AI Image to Video: guida completa con esempi.
3. Reference to Video: Preserva Identità e Stile
Usa Reference to Video quando un prompt da solo non basta. Questa modalità ti consente di caricare più reference e descrivere come dovrebbero controllare il video generato.
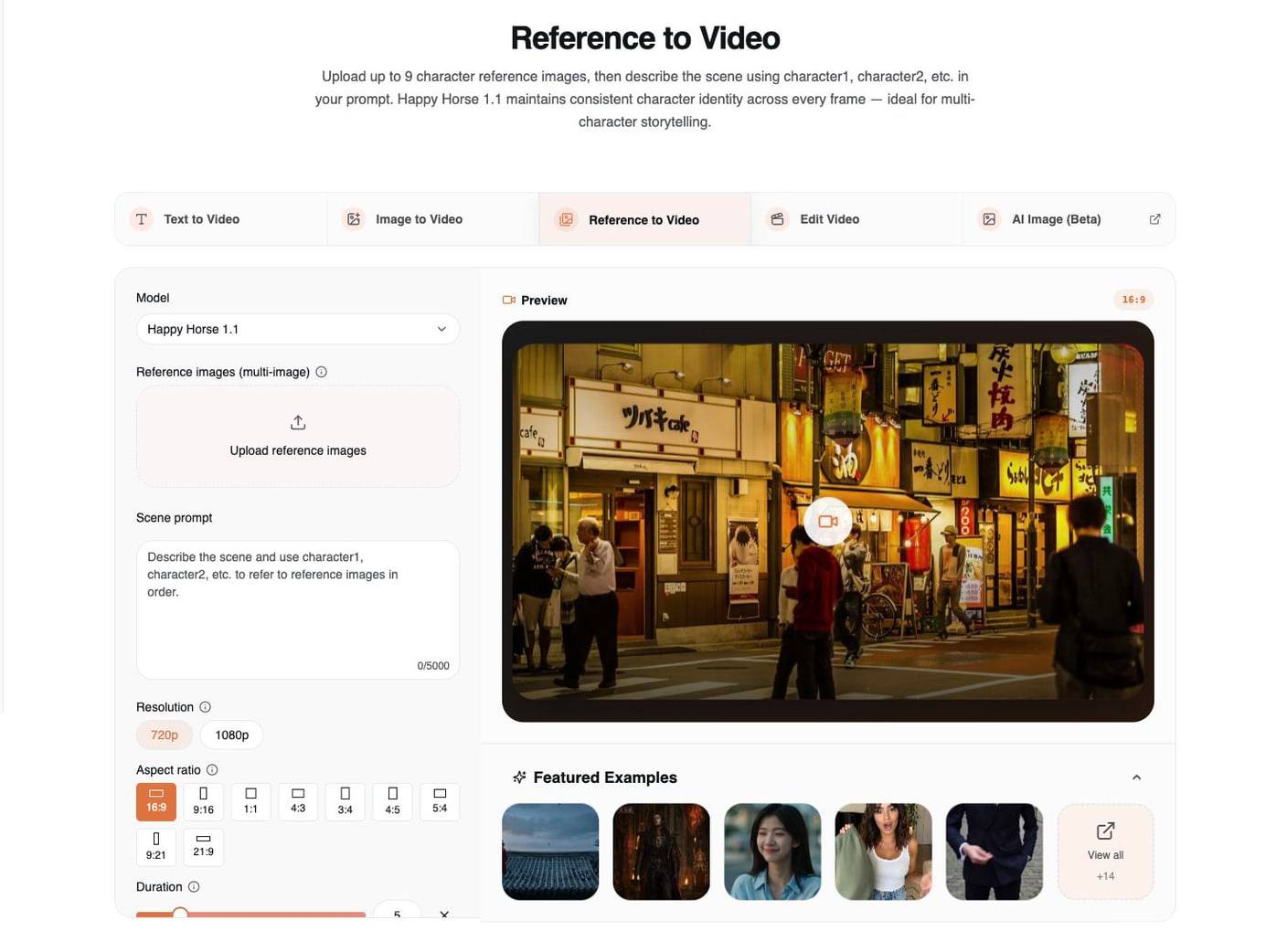
Happy Horse 1.1 supporta fino a 9 immagini reference in questo workflow. La parte importante non è solo caricare le immagini; è nominare chiaramente i loro ruoli nel prompt.
Usa questa struttura:
Usa character1 per [identità/volto/outfit].
Usa character2 per [seconda persona o creatura].
Usa image3 per [location/prodotto/stile].
Descrivi l’azione, la camera, l’illuminazione e l’audio.
Esempio:
Usa character1 come spadaccino, preservando il suo volto, la veste nera e i capelli argentati. Usa character2 come principessa drago, preservando la sua corona e l’armatura sulla spalla simile a scaglie. Si fronteggiano in un cortile di palazzo sotto la pioggia, lento movimento circolare della camera, luce drammatica delle lanterne, movimento di arti marziali contenuto, realismo fantasy cinematografico, 16:9.
Reference-to-video è ideale per:
- coerenza del personaggio tra scene diverse
- storytelling con più personaggi
- video di prodotto in cui l’oggetto deve restare riconoscibile
- concept con influencer o presenter con outfit e dettagli del volto stabili
- campagne adv in cui lo stesso linguaggio visivo deve ripetersi
Gli esempi R2V attualmente in evidenza coprono il giusto spettro: scene di arti marziali, accoppiamenti di personaggi fantasy, cambi di espressione, presentazione live-shopping e prompt focalizzati sugli oggetti. Quando li studi, presta attenzione a come il testo assegna i ruoli delle reference. Un prompt vago come "usa queste immagini" è più debole di "usa character1 per l’identità, image2 per l’outfit e image3 per la forma del prodotto".
Esempi reference-to-video da studiare
L’esempio delle arti marziali è un caso diretto di mappatura dei ruoli: image1 e image2 vengono trattate come i due combattenti, mentre il prompt definisce la scena e l’azione condivise.
L’esempio live-shopping mostra perché R2V è utile oltre il fantasy o l’azione. Il prompt mappa le reference su presenter, outfit, prodotto e ambientazione domestica, poi fornisce battute di parlato temporizzate.
Impostazioni Che Contano in Tutte e Tre le Pagine
La maggior parte delle generazioni fallite deriva da una mancata corrispondenza tra intento e impostazioni, non da un singolo aggettivo sbagliato nel prompt.
| Impostazione | Usala così |
|---|---|
| Duration | Inizia con 5 secondi per i test. Usa 8-10 secondi quando il movimento ha bisogno di tempo per svilupparsi. Evita di chiedere troppi beat d’azione in 3 secondi. |
| Resolution | Itera in 720p; passa a 1080p quando il concept merita di essere rifinito. |
| Aspect ratio | Per text-to-video e reference-to-video, imposta il ratio finale della piattaforma prima della generazione. Per image-to-video, prepara il primo frame con il crop desiderato. |
| Seed | Usalo solo dopo aver trovato una direzione di prompt che vale la pena esplorare. È migliore per variazioni controllate che per salvare un prompt debole. |
| Audio | Attiva l’audio quando dialoghi, ambiente, musica o suono d’azione fanno parte della scena. Se hai bisogno di un loop visivo silenzioso, dillo nel prompt. |
| Reference images | Usa meno reference ma più chiare prima di caricarne tutte e 9. Ogni reference dovrebbe avere un compito. |
Se stai scrivendo prompt da zero, tieni aperto 50 prompt Happy Horse AI che funzionano davvero come supporto. Gli esempi lì sono pattern 1.0 più vecchi, ma la struttura del prompt si trasferisce ancora bene alla 1.1.
Template di Prompt da Riutilizzare
Template text-to-video
[Subject] sta [action] in [environment]. La camera [movement], con [lighting] e [mood]. Includi [audio cue]. Mantieni [style constraint]. Formato: [aspect ratio], [duration].
Template image-to-video
Anima l’immagine caricata con [small motion], [camera movement] e [environmental detail]. Preserva [identity/product shape/composition/lighting]. Evita di modificare [protected detail].
Template reference-to-video
Usa character1 come [role] e preserva [identity details]. Usa image2 come [style/location/product reference]. Crea [scene action] con [camera movement], [lighting] e [audio/mood]. Mantieni coerenti tutte le reference chiave.
Errori Comuni
Errore 1: Chiedere a text-to-video un’identità fissa.
Se l’identità deve restare stabile, usa invece reference-to-video.
Errore 2: Caricare un primo frame debole.
Image-to-video non può correggere in modo affidabile una cattiva illuminazione, una composizione confusa o un’identità del soggetto poco chiara.
Errore 3: Usare ogni immagine reference solo perché puoi.
Sono disponibili nove reference, ma tre reference chiare spesso superano nove ridondanti.
Errore 4: Dimenticare il formato di destinazione.
Un video verticale in stile TikTok e una clip widescreen in stile YouTube non dovrebbero partire dallo stesso ratio.
Errore 5: Sovraccaricare durate brevi.
Non chiedere cinque movimenti di camera, tre emozioni e una sequenza d’azione completa in una clip di 5 secondi. Scegli l’unico momento che conta.
Ricette di Partenza Consigliate
| Obiettivo | Pagina | Impostazioni iniziali | Direzione del prompt |
|---|---|---|---|
| Scena concettuale rapida | Text to Video | 720p, 5s, ratio target | Soggetto chiaro, un’azione, un movimento di camera |
| Loop prodotto per adv social | Image to Video | Immagine prodotto, 1080p finale | Preserva il prodotto, aggiungi nebbia/passaggio luce/lento push-in |
| Beat narrativo del personaggio | Reference to Video | 2-4 reference, 5-8s | Mappa character1, character2, location/stile |
| Test di dialogo o ambiente | Text o Reference | Audio attivo, 5-8s | Scrivi direttamente la battuta o il sound bed |
| Coerenza di campagna | Reference to Video | Stesso set di reference tra i tentativi | Mantieni stabili i ruoli delle reference, varia l’azione della scena |
FAQ
Qual è la modalità migliore di Happy Horse 1.1 da cui iniziare?
Inizia con text-to-video se hai solo un’idea, image-to-video se hai già un’immagine statica finita e reference-to-video se contano identità, forma del prodotto, guardaroba o coerenza di stile.
Happy Horse 1.1 supporta image-to-video?
Sì. Happy Horse 1.1 supporta image-to-video nella pagina dedicata Image to Video. Carica un primo frame, poi usa il prompt di movimento per descrivere il movimento di camera e il movimento della scena.
Quante immagini reference posso usare?
Il workflow reference-to-video di Happy Horse 1.1 supporta fino a 9 immagini reference. Usa etichette di ruolo chiare come character1, character2 o image3 nel prompt così il modello sa cosa controlla ogni reference.
Dovrei usare 720p o 1080p?
Usa 720p per testare i prompt più velocemente e 1080p quando sei pronto a rifinire una direzione forte. La risoluzione non corregge un prompt debole, quindi itera sulla struttura della scena prima di investire di più nella qualità finale.
Happy Horse 1.1 sostituisce video edit?
Non ancora per ogni workflow. Happy Horse 1.1 è l’impostazione predefinita per text-to-video, image-to-video e reference-to-video. Se devi modificare un video esistente, usa l’attuale workflow video-edit finché il supporto edit 1.1 non farà parte del flusso pubblico del generatore.
Prova le Tre Pagine di Happy Horse 1.1
Il passo successivo più semplice è aprire la pagina che corrisponde alla tua risorsa iniziale:
Se stai ancora decidendo cosa è cambiato nel modello stesso, inizia dalla guida al rilascio di Happy Horse 1.1, poi torna qui e testa i tre workflow fianco a fianco.