当你从正确的生成器页面开始时,Happy Horse 1.1 会最容易上手。如果创意还只是一个提示词,请使用 text-to-video;如果你已经有一张很强的首帧图像,请使用 image-to-video;如果角色、产品或风格的一致性比纯粹的提示词自由度更重要,请使用 reference-to-video。
本指南中的截图拍摄于 2026 年 6 月 24 日,来源于已完成公开页面加载的实时 TryHappyHorseAI 生成器。如果你想先了解更全面的版本发布概览,请阅读Happy Horse 1.1 已上线:有哪些变化以及如何使用。如果你想在选择专用页面之前先比较所有创作模式,也可以从 Happy Horse AI 视频生成器中心页开始。本文是实操补充:该打开哪个页面、该调整哪些设置、该如何写提示词,以及该研究哪些示例。
快速工作流地图
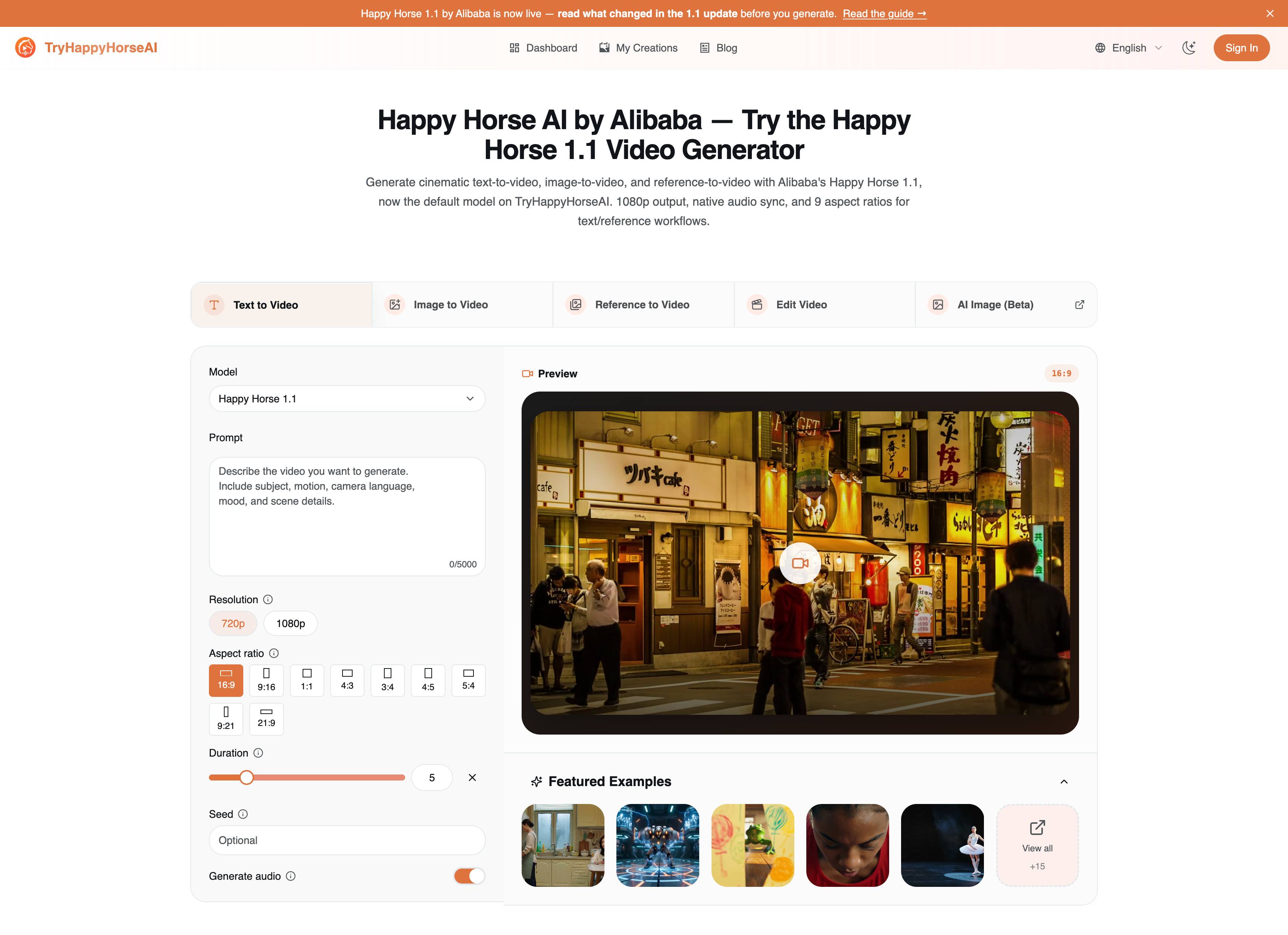
Happy Horse 1.1 的三个创作页面之所以分开,是有原因的。它们都能生成视频,但每个页面都对应不同的起始素材。
| 页面 | 起始内容 | 最适合 | 打开页面 |
|---|---|---|---|
| Text to Video | 一段书面场景描述 | 概念短片、电影感测试、社交媒体创意、广告变体 | 文本生成视频 |
| Image to Video | 一张首帧图像 | 产品动效、人物肖像、海报、视觉循环 | 图片生成视频 |
| Reference to Video | 最多 9 张参考图 | 角色身份、服装、产品细节、重复性活动风格 | 参考图生成视频 |
需要避免的错误,是用更长的提示词去弥补模式选错的问题。如果你已经有准确的产品照片,image-to-video 通常会胜过 text-to-video。如果你需要在新场景中保留同一个人或同一套服装,reference-to-video 通常会胜过前两者。
1. Text to Video:从零构建场景
当场景仍有调整空间时,使用 Text to Video。这是探索创意最快的模式,因为提示词承载了整个镜头:主体、动作、镜头运动、环境、光线、氛围和音频方向。
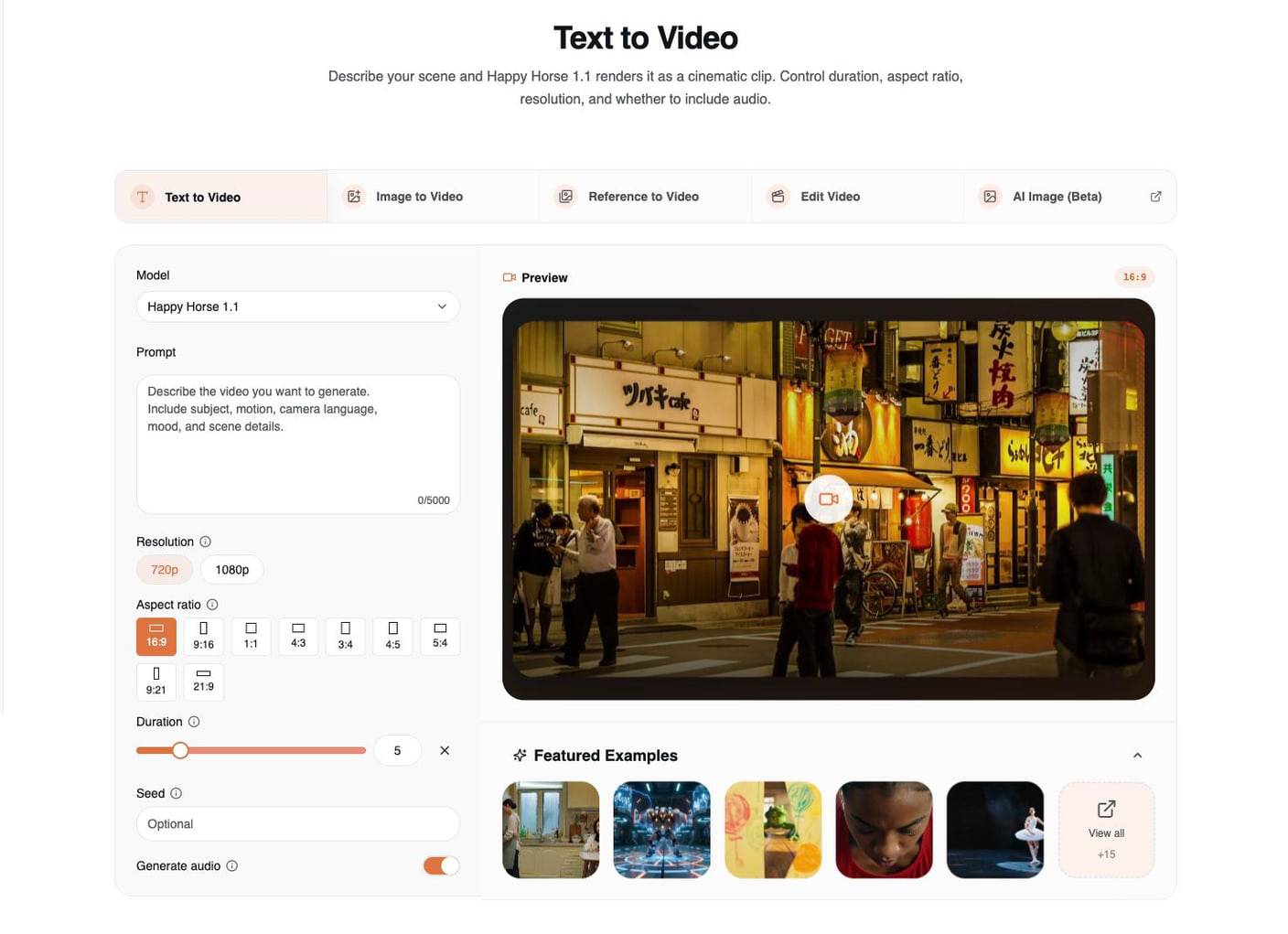
这个页面中最重要的控制项包括:
| 控制项 | 实际用途 |
|---|---|
| Model | 新的 T2V 工作请选择 Happy Horse 1.1。 |
| Prompt | 描述可见场景、镜头运动、氛围和音频。 |
| Resolution | 使用 720p 进行更快迭代,使用 1080p 获得更强的最终渲染效果。 |
| Aspect ratio | 生成前先选好目标格式:16:9、9:16、1:1、4:3、3:4、4:5、5:4、9:21 或 21:9。 |
| Duration | 选择 3 到 15 秒的短视频时长。 |
| Seed | 如果你希望变体路径更具可重复性,请复用同一个种子。 |
| Generate audio | 如果场景适合对白、环境音或动作音效,请保持开启。 |
最清晰的 text-to-video 提示词公式是:
主体 + 动作 + 环境 + 镜头运动 + 光线 + 氛围 + 音频提示 + 格式
示例:
一位专业芭蕾舞者在昏暗的舞台上完成一个有力的大跳,双臂伸展,舞裙在慢动作中飘动。镜头从低位侧面角度跟拍,温暖的聚光灯在地面投下长长的阴影,电影感舞台灯光,细微的布料动态,10 秒,16:9。
当前精选的 T2V 示例很有参考价值,因为它们展示了不同类型的控制方式:多人对话、打斗编排、一镜到底式运动、体育动作以及芭蕾。当你研究这些示例时,少关注题材本身,多关注结构:更强的示例会描述清楚场景里是谁、镜头如何移动、时间推进中发生了什么变化,以及音频应该如何表现。
值得研究的 text-to-video 示例
芭蕾示例是一个很干净的“提示词优先”案例,因为提示词给出了单一主体、舞台环境、镜头风格和明确的动作语言。
多人互动示例适合用于研究对话式提示词。注意它是如何把场景、主体、动作和音频节拍拆开描述的,而不是把整段视频当作一条笼统指令来处理。
2. Image to Video:让首帧动起来
当你已经有了想要的视觉画面时,使用 Image to Video。上传的图像本身已经完成了大量工作,因此提示词应该引导运动,而不是重新定义镜头。
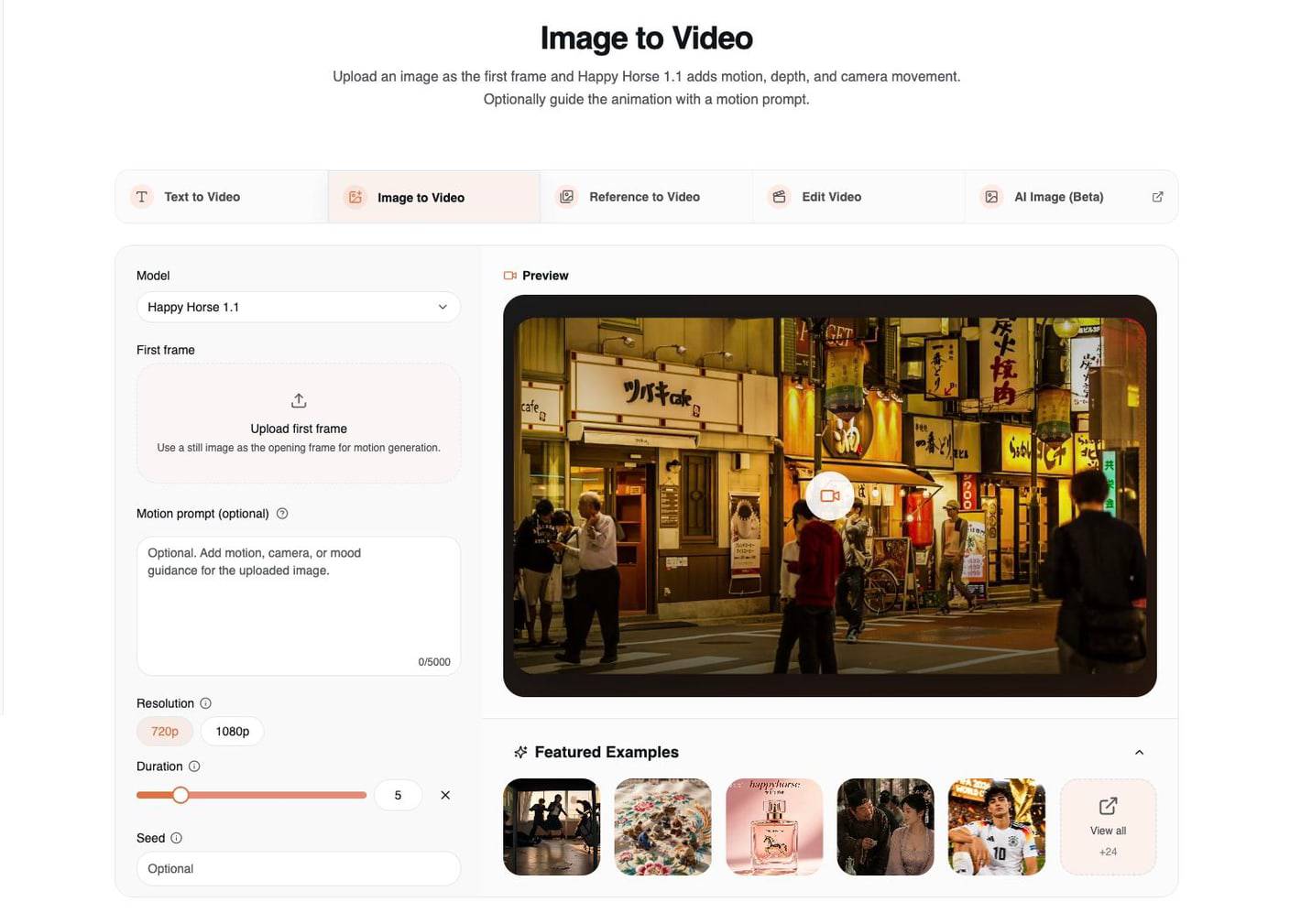
如果源图像已经具备以下特点,image-to-video 的效果会最好:
- 单一且清晰的主体
- 干净明确的光线方向
- 前景与背景层次清楚
- 符合最终视频需求的构图裁切
- 足够多的细节,便于模型保留身份特征或产品形态
实用的提示词公式是:
保留上传图像 + 添加合理运动 + 添加镜头运动 + 保护关键细节
产品图像示例:
让首帧中的香水瓶动起来,加入缓慢而富有电影感的推进镜头,瓶底周围漂浮柔和的琥珀色雾气,玻璃表面有细微的光线扫过,真实反射,保留瓶身形状、标签、颜色和桌面构图。
肖像示例:
让这张肖像产生细微眨眼、自然呼吸、轻柔发丝摆动,并加入缓慢的镜头漂移。保留面部、服装、背景构图和原始光线。
在这个模式下,请在上传前先完成裁切。如果你想做竖屏短视频,就准备竖屏首帧;如果你想做宽屏落地页循环视频,就准备宽屏首帧。image-to-video 并不适合让模型去彻底重构一个已经完成的构图。
当前精选的 I2V 示例适合参考不同类型的源图任务:教室动作场景、细节丰富的手工画面、香水产品镜头,以及古代酒馆风格场景。它们的模式很一致:先有强源图,再加克制的运动。
值得研究的 image-to-video 示例
香水示例是最容易复用到商业项目中的 I2V 模式:保留产品,加入氛围,再通过镜头和光线运动营造高级感。
教室打斗示例属于更难的 I2V 场景。它的参考价值在于,提示词把细节预算用在了因果动作、环境互动和镜头同步上。
如需更深入了解这个工作流,请阅读Happy Horse AI 图片生成视频:完整指南与示例。
3. Reference to Video:保留身份与风格
当仅靠提示词还不够时,使用 Reference to Video。这个模式允许你上传多张参考图,并描述它们应如何控制生成的视频。
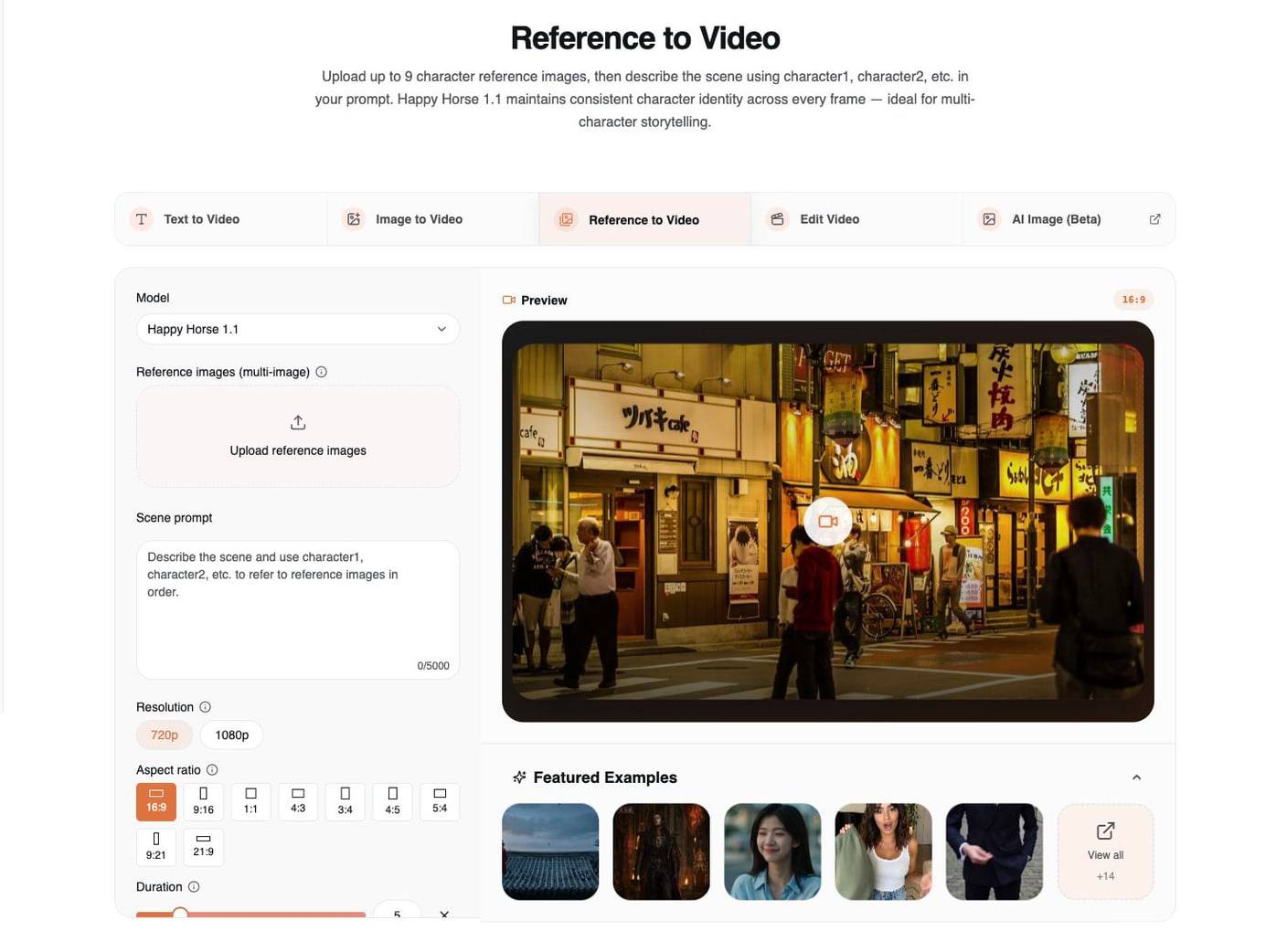
在这个工作流中,Happy Horse 1.1 最多支持 9 张参考图。关键不只是上传图片,更在于在提示词中清楚地命名它们的角色。
请使用以下结构:
Use character1 for [身份/面部/服装].
Use character2 for [第二个人物或生物].
Use image3 for [地点/产品/风格].
Describe the action, camera, lighting, and audio.
示例:
Use character1 as the swordsman, preserving his face, black robe, and silver hair. Use character2 as the dragon princess, preserving her crown and scale-like shoulder armor. They face each other in a rainy palace courtyard, slow circular camera movement, dramatic lantern light, restrained martial arts motion, cinematic fantasy realism, 16:9.
reference-to-video 最适合以下场景:
- 跨场景保持角色一致性
- 多角色叙事
- 必须保持物品可辨识度的产品视频
- 需要稳定服装和面部细节的网红或主播概念
- 需要重复统一视觉语言的广告活动
当前精选的 R2V 示例覆盖范围很合适:武侠场景、奇幻角色配对、表情变化、直播带货展示以及以物体为核心的提示词。当你研究这些示例时,请特别注意文本如何分配参考图角色。像“use these images”这样模糊的提示词,通常不如“use character1 for identity, image2 for outfit, and image3 for product shape”这样明确的写法有效。
值得研究的 reference-to-video 示例
武侠示例是一个直接的角色映射案例:image1 和 image2 被视为两位对战者,而提示词定义了共享场景和动作。
直播带货示例展示了为什么 R2V 的用途不止于奇幻或动作题材。提示词将参考图映射到主播、服装、产品和居家场景,然后再给出按时间推进的台词节奏。
三个页面都重要的设置
大多数生成失败并不是因为提示词里某个形容词写得不好,而是因为创作意图与设置不匹配。
| 设置项 | 正确用法 |
|---|---|
| Duration | 测试时先从 5 秒开始。需要时间铺陈动作时用 8–10 秒。不要在 3 秒里安排过多动作节拍。 |
| Resolution | 先用 720p 迭代;当概念值得打磨时再切到 1080p。 |
| Aspect ratio | 对于 text-to-video 和 reference-to-video,请在生成前就设置最终发布平台比例。对于 image-to-video,请按你想要的裁切准备首帧。 |
| Seed | 只有在你已经找到值得深入探索的提示词方向后再使用。它更适合做受控变体,而不是拯救一个弱提示词。 |
| Audio | 当对白、环境音、音乐或动作音效是场景组成部分时,请开启音频。如果你需要无声的视觉循环,请在提示词中明确写出。 |
| Reference images | 与其一口气上传 9 张,不如先用更少但更清晰的参考图。每一张参考图都应承担明确任务。 |
如果你正在从零开始写提示词,建议同时打开 50 个真正有效的 Happy Horse AI 提示词 作为参考。那里的示例属于较早的 1.0 模式,但提示词结构依然可以很好地迁移到 1.1。
可复用的提示词模板
text-to-video 模板
[主体]正在[动作],场景位于[环境]中。镜头[运动方式],配合[光线]和[氛围]。加入[audio cue]。保持[风格约束]。格式:[宽高比],[时长]。
image-to-video 模板
让上传的图像产生[小幅运动]、[镜头运动]和[环境细节]。保留[身份/产品形态/构图/光线]。避免改变[受保护细节]。
reference-to-video 模板
Use character1 as [role] and preserve [identity details]. Use image2 as [style/location/product reference]. Create [scene action] with [camera movement], [lighting], and [audio/mood]. Keep all key references consistent.
常见错误
错误 1:让 text-to-video 负责固定身份。
如果身份必须稳定,请改用 reference-to-video。
错误 2:上传质量较弱的首帧。
image-to-video 无法稳定修复糟糕的光线、杂乱的构图或不清晰的主体身份。
错误 3:因为能用就把所有参考图都上传。
虽然最多支持九张参考图,但三张清晰的参考图往往比九张重复参考图更有效。
错误 4:忘记目标格式。
TikTok 风格的竖屏视频和 YouTube 风格的宽屏片段,不应该从同一个比例开始。
错误 5:在短时长里塞入过多内容。
不要在 5 秒视频里要求五次镜头移动、三种情绪和一整段动作戏。选出那个最重要的瞬间即可。
推荐起步方案
| 目标 | 页面 | 起始设置 | 提示词方向 |
|---|---|---|---|
| 快速概念场景 | Text to Video | 720p、5 秒、目标比例 | 清晰主体、一个动作、一个镜头运动 |
| 社交广告产品循环 | Image to Video | 产品图、最终使用 1080p | 保留产品,加入雾气/扫光/缓慢推进 |
| 角色剧情节点 | Reference to Video | 2–4 张参考图、5–8 秒 | 映射 character1、character2、地点/风格 |
| 对话或环境音测试 | Text 或 Reference | 开启音频、5–8 秒 | 直接写出口播台词或声音底氛 |
| 活动视觉一致性 | Reference to Video | 各次尝试使用同一组参考图 | 固定参考图角色,只变化场景动作 |
FAQ
Happy Horse 1.1 最适合从哪种模式开始?
如果你只有一个想法,就从 text-to-video 开始;如果你已经有一张完成的静态图像,就用 image-to-video;如果身份、产品形态、服装或风格一致性很重要,就用 reference-to-video。
Happy Horse 1.1 支持 image-to-video 吗?
支持。Happy Horse 1.1 在专用的 Image to Video 页面提供 image-to-video。上传一张首帧,然后用运动提示词描述镜头运动和场景动态。
我最多可以使用多少张参考图?
Happy Horse 1.1 的 reference-to-video 工作流最多支持 9 张参考图。请在提示词中使用清晰的角色标签,例如 character1、character2 或 image3,让模型知道每张参考图控制什么内容。
我应该使用 720p 还是 1080p?
使用 720p 进行更快的提示词测试,在你准备打磨一个强方向时再用 1080p。分辨率无法修复弱提示词,因此在投入更高最终画质之前,先迭代场景结构。
Happy Horse 1.1 会取代视频编辑吗?
目前还不能覆盖所有工作流。Happy Horse 1.1 目前是 text-to-video、image-to-video 和 reference-to-video 的默认方案。如果你需要编辑现有视频,请继续使用当前的视频编辑工作流,直到 1.1 的编辑支持进入公开生成器流程。
试用这三个 Happy Horse 1.1 页面
最简单的下一步,就是打开与你起始素材相匹配的页面:
如果你还在了解模型本身到底改变了什么,请先阅读 Happy Horse 1.1 发布指南,然后再回到这里,并排测试这三种工作流。